PGS Catalog Ancestry Documentation
This page contains information about how participant ancestry is cataloged and represented for scores and sample descriptions in the PGS Catalog.
Essential to the interpretation of PGS data is the accurate description of the ancestry of samples included in these studies. The PGS Catalog describes the ancestry of samples, in a standardized manner, according to the published framework developed by the NHGRI-EBI GWAS Catalog and endorsed in the recent Polygenic Risk Score Reporting Standards (PRS-RS). Sample ancestry is represented in two forms: (1) an ancestry category from a controlled list and (2) a more detailed ancestry name/description (if available). Detailed descriptions aim to capture accurate, informative, and comprehensive information regarding the ancestry or genealogy of each distinct sample. Category assignment reduces complexity within data sets and enables the establishment of hierarchical relationships, placing samples in context with other samples, groups, and populations.
See also the PGS Catalog Data Description page for a complete description of the metadata captured for samples in PGS studies.
Ancestry Categories
Each sample description is mapped to an ancestry category and the samples are combined if they belong to the same category. We attempt to report ancestry-specific sample descriptions (e.g. sample sizes and case/control breakdowns); however, this is not always possible and samples can be labelled with more than one broad ancestry category.
A complete list of ancestry categories used in the PGS Catalog (adapted from Table 1, Morales et al 2018) can be found below:
| Ancestry category | Display category (for charts) | Definition |
|---|---|---|
| Aboriginal Australian | Additional Diverse Ancestries | Includes individuals who either self-report or have been described by authors as Australian Aboriginal. These are expected to be descendants of early human migration into Australia from Eastern Asia and can be distinguished from other Asian populations by mtDNA and Y chromosome variation. |
| African American or Afro-Caribbean | African | Includes individuals who either self-report or have been described by authors as African American or Afro-Caribbean. This category also includes individuals who genetically cluster with reference populations from this region, for example, 1000 Genomes and/or HapMap ACB or ASW populations. We note that there is likely to be significant admixture with European ancestry populations. |
| African unspecified | African | Includes individuals that either self-report or have been described as African, but there was not sufficient information to allow classification as African American, Afro-Caribbean or Sub-Saharan African. |
| Asian unspecified | Additional Asian Ancestries (including Central, and South East Asian) | Includes individuals that either self-report or have been described as Asian but there was not sufficient information to allow classification as East Asian, Central Asian, South Asian, or South-East Asian. |
| Central Asian | Additional Asian Ancestries (including Central, and South East Asian) | Includes individuals who either self-report or have been described by authors as Central Asian. We note that there does not appear to be a suitable reference population for this population and efforts are required to fill this gap. |
| East Asian | East Asian | Includes individuals who either self-report or have been described by authors as East Asian or one of the sub-populations from this region (e.g., Chinese). This category also includes individuals who genetically cluster with reference populations from this region, for example, 1000 Genomes and/or HapMap CDX, CHB, CHS, and JPT populations. |
| European | European | Includes individuals who either self-report or have been described by authors as European, Caucasian, white, or one of the sub-populations from this region (e.g., Dutch). This category also includes individuals who genetically cluster with reference populations from this region, for example, 1000 Genomes and/or HapMap CEU, FIN, GBR, IBS, and TSI populations. |
| Greater Middle Eastern (Middle Eastern, North African or Persian) | Greater Middle Eastern (Middle Eastern, North African or Persian) | Includes individuals who self-report or were described by authors as Middle Eastern, North African, Persian, or one of the sub-populations from this region (e.g., Saudi Arabian). We note there is heterogeneity in this category with different degrees of admixture as well as levels of genetic isolation. We note that there does not appear to be a suitable reference population for this category and efforts are required to fill this gap. |
| Hispanic or Latin American | Hispanic or Latin American | Includes individuals who either self-report or are described by authors as Hispanic, Latino, Latin American, or one of the sub-populations from this region. This category includes individuals with known admixture of primarily European, African, and Native American ancestries, though some may have also a degree of Asian (e.g., Peru). We also note that the levels of admixture vary depending on the country, with Caribbean countries carrying higher levels of African admixture when compared to South American countries, for example. This category also includes individuals who genetically cluster with reference populations from this region, for example, 1000 Genomes and/or HapMap CLM, MXL, PEL, and PUR populations. |
| Native American | Additional Diverse Ancestries | Includes indigenous individuals of North, Central, and South America, descended from the original human migration into the Americas from Siberia. We note that there does not appear to be a suitable reference population for this category and efforts are required to fill this gap. |
| Not reported | Ancestry Not Reported | Includes individuals for which no ancestry or country of recruitment information is available. |
| Oceanian | Additional Diverse Ancestries | Includes individuals that either self-report or have been described by authors as Oceanian or one of the sub-populations from this region (e.g., Native Hawaiian). We note that there does not appear to be a suitable reference population for this category and efforts are required to fill this gap. |
| Other | Additional Diverse Ancestries | Includes individuals where an ancestry descriptor is known but insufficient information is available to allow assignment to one of the other categories. |
| Other admixed ancestry | Additional Diverse Ancestries | Includes individuals who either self-report or have been described by authors as admixed and do not fit the definition of the other admixed categories already defined (“African American or Afro-Caribbean” or “Hispanic or Latin American”). |
| South Asian | South Asian | Includes individuals who either self-report or have been described by authors as South Asian or one of the sub-populations from this region (e.g., Asian Indian). This category also includes individuals who genetically cluster with reference populations from this region, for example, 1000 Genomes and/or HapMap BEB, GIH, ITU, PJL, and STU populations. |
| South East Asian | Additional Asian Ancestries (including Central, and South East Asian) | Includes individuals who either self-report or have been described by authors as South East Asian or one of the sub-populations from this region (e.g., Vietnamese). This category also includes individuals who genetically cluster with reference populations from this region, for example, 1000 Genomes KHV population. We note that East Asian and South East Asian populations are often conflated. However, recent studies indicate a unique genetic background for South East Asian populations. |
| Sub-Saharan African | African | Includes individuals who either self-report or have been described by authors as Sub-Saharan African or one of the sub-populations from this region (e.g., Yoruban). This category also includes individuals who genetically cluster with reference populations from this region, for example, 1000 Genomes and/or HapMap ESN, LWK, GWD, MSL, MKK, and YRI populations. |
| Multi-Ancestry (including Europeans) | Multi-Ancestry (including Europeans) | Combined sample of multiple ancestries that includes European ancestry individuals. Used when ancestry-specific sample sizes are unknown or not being considered (e.g. in combined samples). |
| Multi-Ancestry (excluding Europeans) | Multi-Ancestry (excluding Europeans) | Combined sample of multiple ancestries that does not include any European ancestry individuals. Used when ancestry-specific sample sizes are unknown or not being considered (e.g. in combined samples). |
To reduce the complexity of displaying the data some of the ancestry categories have been merged into higher-level groupings (Display categories) - these groupings represent the current breadth of data in the PGS Catalog and we plan to review and update these groupings as more data is added.
Displaying Ancestry Distributions
We provide visual summaries of participant ancestry within each stage of PGS development (source of variant associations [GWAS], and score development/training) and evaluation. Here, we outline how the ancestry distribution is calculated in each stage:
PGS Development
| Study stage | Distribution calculation | Example |
|---|---|---|
| Source of Variant Associations (GWAS) |
A count of the total number of individuals in each ancestry display category across all GWAS samples used to develop the score. Samples are labelled Multi-ancestry (including or excluding Europeans) if ancestry-specific numbers are not available (see example). The relative proportion of each ancestry group is displayed as a percentage of the total number of individuals. |
Distribution:
Multi-Ancestry (including Europeans): 50% (2500 individuals out of 5000 individuals)
European: 30% (1500 individuals out of 5000 individuals)
East Asian: 20% (1000 individuals out of 5000 individuals)
|
| Score Development/Training | Calculated the same as above, except for samples used for Score Development/Training. | |
PGS Evaluation
| Study stage | Distribution calculation | Example |
|---|---|---|
| PGS Evaluation |
The calculation of the ancestry distribution for samples used in PGS Evaluation is different from those in development, to highlight the range of ancestries represented in this stage instead of their relative sample sizes. To calculate the ancestry distribution for PGS Evaluation we first assign an ancestry label to each unique Sample Set the PGS has been applied to. Samples are labelled Multi-ancestry (including or excluding Europeans) if more than one ancestry is present in the combined Sample Set (see example). The distribution is calculated by dividing the number of Sample Sets with the same ancestry category by the total number of Sample Sets. This can be interpreted as the percentage of a scores’ performance data that is derived from a specific ancestry group; however, it should be noted that the percentage does not account for sample size differences between the sample sets for simplicity. |
Example with 4 Sample Sets to evaluate the same polygenic score: Sample Set A
Combined ancestry:
Multi-ancestry (including European)
Sample Set B
Combined ancestry:
African
Sample Set C
Combined ancestry:
East Asian
Sample Set D
Combined ancestry:
African
Distribution:
African: 50% (2 Sample Sets [B & D] out of 4 Sample Sets)
East Asian: 25% (1 Sample Set [C] out of 4 Sample Sets)
Multi-ancestry (including European): 25% (1 Sample Set [A] out of 4 Sample Sets)
|
Example
Here is an example of the ancestry distributions for a single score (PGS000018). You can hover over the pie charts to see the list of ancestries included and their proportions, as well as the total sample sizes.
| Polygenic Score ID & Name | PGS Publication ID (PGP) | Reported Trait | Mapped Trait(s) (Ontology) | Number of Variants |
Ancestry distribution GWAS Dev Eval |
Scoring File (FTP Link) |
|---|---|---|---|---|---|---|
| PGS000018 (metaGRS_CAD) |
PGP000007 | Inouye M et al. J Am Coll Cardiol (2018) |
Coronary artery disease | coronary artery disorder | 1,745,179 | https://ftp.ebi.ac.uk/pub/databases/spot/pgs/scores/PGS000018/ScoringFiles/PGS000018.txt.gz |
Filtering PGS by Ancestry
Users may be interested in finding PGS that have been developed or evaluated with data from a particular ancestry group. To facilitate this we’ve implemented filters on the PGS browsing, Publication and Trait pages that show/hide scores based on the ancestry data and criteria you select. With this comes two display options that easily allow users to identify PGS using multi-ancestry data or scores that are ‘non-European’ (e.g. contain no European ancestry data).
The data can be filtered with two selections: (1) selecting the stage of the PGS study design you’re interested in querying, (2) selecting the ancestry category you are interested in viewing data for.
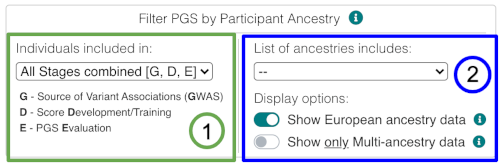
1 - Study stages
First, you need to select on which PGS stage you want to filter the ancestries (all of the data is displayed by default). The first dropdown contains the possibile stages of a PGS study that can be queried:
| All Stages combined [G, D, E] | Corresponds to the combination of the stages "Source of Variant Associations (GWAS)", "Score Development/Training" and "Score Evaluation". |
| Development [G, D] | Corresponds to the combination of the stages "Source of Variant Associations (GWAS)" and "Score Development/Training" |
| GWAS [G] | Corresponds to the stage "Source of Variant Associations (GWAS)". |
| Score Development/Training [D] | Corresponds to the stage "Score Development/Training". |
| PGS Evaluation [E] | Corresponds to the stage "PGS Evaluation". |
2 - Ancestry selection
Second, you can show/hide PGS based on the ancestries of participants in the study stage you selected. The options are as follows:
|
List of ancestries includes: ("Select an ancestry" dropdown) |
Filter PGS that include data of individuals from the selected ancestry at the selected study stage. This also filters the contributing ancestries within the Multi-ancestry labels (where specific sample size information is unavailable). | |
| Display Options: | Show European ancestry data [default: on] | This button can be used to hide PGS with any European ancestry data to only show scores with data from other non-European ancestry groups. The button is selected by default, displaying all PGS. |
| Show only Multi-ancestry data [default: off] | Shows only PGS that include data from multiple ancestry groups at the selected study stage, hiding PGS with data from a single ancestry group. | |
Example Use Cases
Here are some examples of common filter combinations/use-cases that may be relevant to users looking to match their PGS to samples based on reported ancestry labels.
-
Find scores developed using a multi-ancestry GWAS.
Study stage: GWAS [G] List of ancestries includes: --[default option] Show European ancestry data: on [default option] Show only Multi-ancestry data: on -
Identify non-European scores (e.g. those that did not include European ancestry individuals in development)
Study stage: Development [G, D] List of ancestries includes: --[default option] Show European ancestry data: off Show only Multi-ancestry data: off [default option] -
Find scores with performance measured in a specific ancestry group. Here is an example of the settings needed to find scores evaluated in East Asian ancestry individuals:
Study stage: PGS Evaluation [E] List of ancestries includes: East Asian Show European ancestry data: on [default option] Show only Multi-ancestry data: off [default option]
References
Morales et al.
Genome Biology (2018) 19:21
Wand, Lambert et al.
Improving reporting standards for polygenic scores in risk prediction studies
Nature (2021) 591, 211–219